
이미지 분류
이미지 분류는 컴퓨터가 사람처럼 시각적으로 사물을 인식하고 분류하는 Computer Vision 분야의 핵심 작업에 해당한다.
CNN(합성곱 신경망)은 기존 신경망보다 정교한 분석이 가능하며, 깊은 층을 통해 이미지의 특징을 고도화된 필터로 추출한다.
분류 유형
- 이진 분류(Binary): 두 개의 클래스(예: 정상/비정상) 중 하나로 분류한다.
- 다중 클래스(Multiclass): 세 개 이상의 클래스 중 하나로 분류한다(예: 고양이/개/토끼).
- 다중 라벨(Multilabel): 한 이미지가 여러 라벨을 동시에 가질 수 있다.
- 계층적 분류(Hierarchical): 클래스가 계층 구조로 조직되어 상위-하위 개념을 구분한다.
핵심 단계
- 데이터 수집: 충분한 양의 이미지와 라벨을 확보한다.
- 특징 추출: 이미지에서 의미 있는 특징(엣지, 색상, 질감 등)을 추출한다.
- 분류: 추출된 특징을 바탕으로 이미지를 올바른 클래스에 할당한다.
전이학습(Transfer Learning):
사전학습된 모델의 가중치를 재사용해 적은 데이터로도 높은 성능을 낼 수 있다.
CNN 구성요소
| 구성요소 | 역할 및 설명 |
|---|---|
| 입력층(Input Layer) | 원본 이미지의 픽셀 데이터를 입력받는다. 이미지의 크기(예: 224x224x3)가 입력 크기를 결정한다. |
| 합성곱층(Convolutional Layer) | 여러 개의 필터(커널)를 이미지에 슬라이딩하며 지역적 특징(엣지, 패턴 등)을 추출한다. 각 필터는 특성 맵을 만든다. |
| 활성화 함수(Activation Function) | 주로 ReLU를 사용한다. 음수 값을 0으로 바꿔주고, 비선형성을 부여해 복잡한 패턴 학습이 가능하게 한다. |
| 풀링층(Pooling Layer) | 특성 맵의 공간적 크기를 줄여 계산량을 감소시키고 과적합을 방지한다. Max pooling(최댓값 추출)이 대표적이다. |
| 완전 연결층(Fully Connected Layer) | 추출된 특징을 1차원 벡터로 변환(flatten)한 후, 모든 뉴런이 서로 연결되어 최종 분류를 진행한다. |
| 출력층(Output Layer) | 클래스별 확률값을 출력한다. 다중 클래스 분류에서는 Softmax 함수로 확률값을 정규화한다. |
| 드롭아웃(Dropout, 선택적) | 일부 뉴런을 무작위로 비활성화해 과적합을 방지하는 정규화 기법이다. |
합성곱(Convolution) 연산
- 입력 이미지에 작은 필터(예: 3x3)를 슬라이딩하며 곱셈·합산을 반복해 특징 맵을 생성한다.
- 필터의 개수만큼 여러 특징 맵이 만들어지며, 각 필터는 엣지, 질감 등 특정 패턴에 반응한다.
- 필터의 이동 간격은 stride, 경계 처리를 위한 패딩(padding) 등도 주요 파라미터에 해당한다.
풀링(Pooling) 연산
- MaxPooling(최댓값), AveragePooling(평균값) 등이 있으며, 공간 정보를 요약해 연산량을 줄이고, 위치 변화에 강인한 특징을 학습한다.
- GlobalAveragePooling은 전체 맵의 평균값만 남겨 FC층 전에 차원을 크게 줄일 수 있다.
Flatten & FC Layer
- 합성곱·풀링을 반복한 후, 결과를 1차원 벡터로 변환(flatten)하여 완전 연결층에 입력한다.
- FC층은 전통적인 신경망처럼 모든 뉴런이 서로 연결되어 최종 분류를 담당한다.
이미지 학습과정
데이터 준비 및 전처리
- 이미지 수집 및 라벨링:
충분한 양의 이미지를 수집하고, 각 이미지에 라벨(정답)을 부여한다. - 데이터 증강(Data Augmentation):
회전, 뒤집기, 밝기 조정, 확대/축소 등으로 데이터 다양성을 확보하고 과적합을 방지한다. - 정규화 및 리사이즈:
픽셀 값을 0~1 범위로 정규화하고, 모델 입력 크기에 맞게 리사이즈한다.
ImageDataGenerator
Keras 등에서 제공하는 ImageDataGenerator를 활용하면, 실시간으로 데이터 증강 및 전처리를 자동화할 수 있다.
flow_from_directory: 디렉토리 구조별로 이미지를 불러오고 자동 라벨링한다.flow_from_dataframe: DataFrame에서 경로와 라벨을 읽어 배치 단위로 불러온다.
특징 추출 및 모델 학습
- 합성곱/풀링/활성화:
CNN의 여러 층을 거치며 이미지로부터 점점 더 추상적인 특징을 자동으로 추출한다. - 완전 연결층:
추출된 특징을 바탕으로 최종적으로 클래스별 확률을 산출한다.
평가 및 검증
- 검증 데이터셋 활용:
학습에 사용하지 않은 별도의 데이터로 모델 성능을 평가한다. - 성능 개선:
필요시 하이퍼파라미터를 조정하거나 데이터 증강, 레이어 추가 등으로 성능을 개선한다.
테스트 및 배포
- 실제 환경에서 미지의 이미지를 분류하여 모델의 실전 성능을 검증한다.
CNN 아키텍처
| 아키텍처 | 주요 특징 및 구조 |
|---|---|
| LeNet-5 | 1998년에 제안되었으며, 2개의 합성곱+풀링층과 3개의 완전 연결층으로 구성된다. 소형 이미지(28x28, MNIST 등) 분류에 적합하다. |
| AlexNet | 2012년 ILSVRC에서 우승하였으며, 5개의 합성곱층+3개의 완전 연결층, ReLU 활성화 함수 도입, 대규모 이미지(224x224) 분류에 사용된다. |
| VGG-16 | 13개의 합성곱층+3개의 완전 연결층, 모든 합성곱 커널 크기를 3x3으로 통일하여 깊은 구조(16층)로 일관된 구조를 가진다. |
| ResNet | 2015년 ILSVRC에서 우승하였으며, 50~152개 층의 초심층 구조와 잔차 연결(residual connection)로 학습 효율을 극대화한다. |
| Inception | 다양한 크기의 필터를 병렬로 적용(Inception 모듈), 1x1 합성곱으로 연산량을 감소시키고 GlobalAveragePooling을 사용한다. |
| MobileNet | 모바일/임베디드 환경에 최적화된 경량화 구조로 실시간 분류가 가능하다. |
전이학습(Transfer Learning) 활용
최신 실무에서는 사전학습된 CNN 모델을 가져와 출력층만 교체하거나 일부 층만 미세조정(Fine-tuning)하여 적은 데이터로도 좋은 성능을 얻는다.
공통 구조
입력 → [합성곱 → 활성화 → 풀링] × N → (필요시 드롭아웃) → 완전 연결층 → 출력(Softmax) 순으로 진행한다.
특징
-
특징 추출부(Feature Extractor):
여러 합성곱/풀링층이 반복되어 이미지의 저수준(엣지)부터 고수준(객체)까지 특징을 추출한다. -
분류부(Classifier):
완전 연결층에서 추출된 특징을 바탕으로 클래스별 확률을 산출한다.
정리
- 이미지 분류는 이미지를 클래스별로 자동 분류하는 작업이며, CNN은 이를 위한 대표적 딥러닝 모델이다.
- CNN은 입력층, 합성곱층, 활성화함수, 풀링층, 완전 연결층, 출력층 등으로 구성되며, 각 층이 계층적으로 쌓여 특징을 추출하고 분류를 수행한다.
- 학습과정은 데이터 준비, 전처리, 모델 학습, 평가, 테스트 순으로 진행한다.
- 대표적인 CNN 아키텍처로는 LeNet, AlexNet, VGG, ResNet, Inception, MobileNet 등이 있으며, 각각의 구조와 특징이 다르다.
실습
학습 목표
- CNN의 기본 개념과 이미지 분류에서의 역할을 이해한다.
- CNN의 주요 구성요소(입력층, 합성곱층, 활성화 함수, 풀링층, 완전 연결층 등)를 설명할 수 있다.
- 이미지 학습과정(데이터 준비, 전처리, 모델 학습, 평가, 테스트)을 이해한다.
- 학습곡선을 해석하고 오버피팅 문제를 인식하며, 개선 방법을 습득한다.
- 딥러닝 모델의 하이퍼파라미터 튜닝과 전이학습 활용법을 이해한다.
CNN Layer 구현
CNN 모델 디자인
from tensorflow.keras import models, layers
model = models.Sequential()
# (32, 32, 3) => (30, 30, 32)
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))
# (30, 30, 32) => (15, 15, 32)
model.add(layers.MaxPool2D(pool_size=(2, 2)))
# (15, 15, 32) => (13, 13, 64)
model.add(layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
# (13, 13, 64) => (6, 6, 64)
model.add(layers.MaxPool2D(pool_size=(2, 2)))
# (6, 6, 64) => (4, 4, 64)
model.add(layers.Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
# 3D를 1D로 변환
model.add(layers.Flatten())
# Classification : Fully Connected Layer 추가
model.add(layers.Dense(units=64, activation='relu'))
model.add(layers.Dense(units=10, activation='softmax'))
# 모델의 학습 정보 설정
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
# 모델 학습
history = model.fit(x=train_x, y=train_y, epochs=20, batch_size=256, verbose=2, validation_split=0.2)
| Accuracy | Loss |
|---|---|
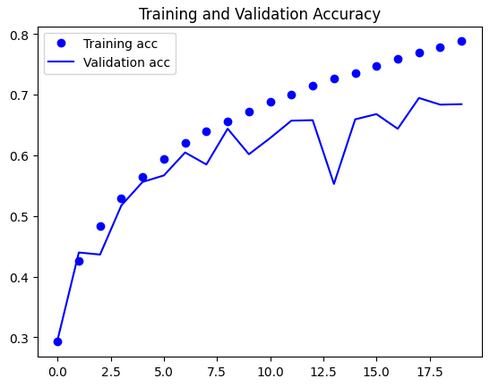 |
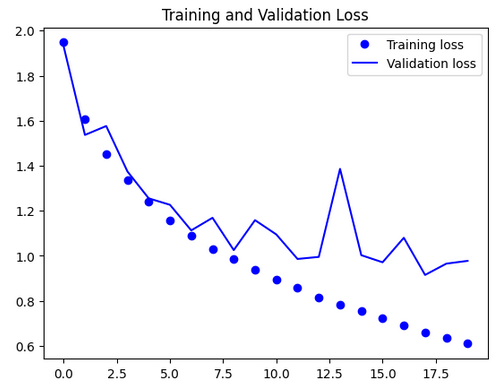 |

학습곡선 해석 및 오버피팅 개선 방안
1. 그래프 해석
- Training Accuracy/Loss
- 학습 정확도는 꾸준히 상승하여 0.9(90%)에 근접한다.
- 학습 손실(loss)은 꾸준히 감소해 0.4 이하로 떨어진다.
- Validation Accuracy/Loss
- 검증 정확도는 0.8(80%) 부근에서 더 이상 오르지 않고, 에포크가 진행될수록 상승이 멈추거나 약간 하락/변동한다.
- 검증 손실은 0.7~0.8 선에서 변동하며, 오히려 에포크가 늘수록 올라가기도 한다.
2. 원인 분석
-
오버피팅(overfitting) 현상.
- 오버피팅이란?
- 모델이 학습 데이터에는 매우 잘 맞지만, 새로운 데이터(검증/테스트)에는 일반화가 잘 안 되는 상태.
- 구체적 신호
- 학습 손실은 계속 감소(=학습 데이터에 점점 더 잘 맞춤)
- 검증 손실은 어느 순간부터 더 이상 감소하지 않고, 오히려 증가하거나 불안정하게 변동
- 학습 정확도와 검증 정확도의 차이가 점점 커짐
3. 왜 이런 현상이 생기나?
- 모델이 너무 복잡하거나 파라미터가 많을 때
- 학습 데이터에 비해 검증 데이터의 분포가 다를 때
- 데이터가 충분히 다양하지 않거나, 데이터 증강이 부족할 때
- 드롭아웃, 정규화 등 일반화 기법이 부족할 때
- 에포크 수가 너무 많아 불필요하게 오래 학습할 때
4. 이런 경우 어떻게 해야 하나?
- Early Stopping(조기 종료) 사용:
- 검증 손실이 더 이상 감소하지 않으면 학습을 멈춘다.
- 드롭아웃(Dropout)·정규화(BatchNorm) 추가:
- 모델이 일부 뉴런에 의존하지 않도록 하고, 학습을 안정화한다.
- 데이터 증강(Data Augmentation):
- 학습 데이터를 회전, 이동, 노이즈 추가 등으로 다양하게 만든다.
- 모델 단순화:
- 층 수나 파라미터 수를 줄여 복잡도를 낮춘다.
- 학습률(learning rate) 조정:
- 너무 높으면 불안정, 너무 낮으면 과적합으로 이어질 수 있다.
- 더 많은 데이터 확보:
- 가능하다면 데이터셋을 키운다.
5. 참고: 정상적인 학습곡선은?
- 학습·검증 손실이 모두 점진적으로 감소
- 학습·검증 정확도가 모두 점진적으로 증가
- 두 곡선 간의 차이가 크지 않음
- (차이가 크면 오버피팅, 둘 다 낮으면 언더피팅)
결론
-
현재 학습곡선은 모델이 학습 데이터에는 과하게 맞추고, 새로운 데이터에는 일반화하지 못하는 전형적인 오버피팅 상태다.
CNN 모델 개선
-
드롭아웃(Dropout)·정규화(BatchNorm) 추가:
-
학습률(learning rate) 조정:
from tensorflow.keras import models, layers
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(BatchNormalization())
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(layers.MaxPool2D((2, 2)))
model.add(Dropout(0.5))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(layers.MaxPool2D((2, 2)))
model.add(Dropout(0.5))
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer=Adam(learning_rate=0.0002), loss='categorical_crossentropy', metrics=['accuracy'])
history = model.fit(x=train_x, y=train_y, epochs=50, batch_size=128, validation_split=0.2, verbose=2)
| Accuracy | Loss |
|---|---|
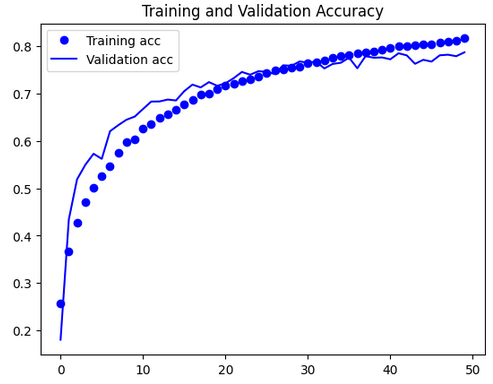 |
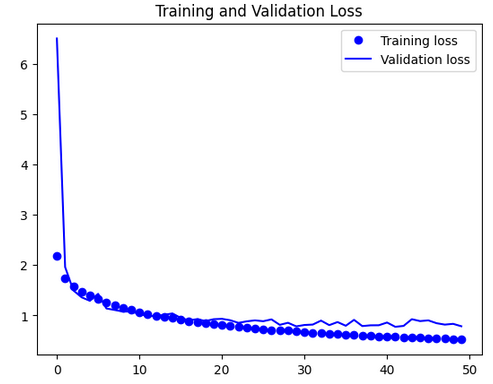 |

결론
이번 학습을 통해 합성곱 신경망(CNN)의 구조와 원리를 이해하고, 실제 이미지 분류 문제에 적용해봄으로써 딥러닝 기반 컴퓨터 비전의 핵심 개념을 익혔다.
CNN의 다양한 구성요소와 대표 아키텍처의 특징, 데이터 전처리와 정규화, 오버피팅 방지 기법 등 실전적인 내용을 학습함으로써,
이미지 분류 모델의 성능을 효과적으로 향상시키는 방법을 습득할 수 있었다.
향후에는 전이학습, 데이터 증강, 하이퍼파라미터 튜닝 등 고급 기법을 적극적으로 활용하여,
더 높은 성능과 실전 적용 능력을 갖춘 딥러닝 모델을 설계·활용할 수 있을 것이다.