
(Mnist, Cifar_10) Dataset
1. 데이터셋 및 코드 개요
❓ Mnist 데이터셋이란?
-
손으로 쓴 숫자(0~9)를 인식하는 머신러닝 및 딥러닝 모델의 성능 평가를 위해 널리 사용되는 대표적인 이미지 데이터셋이다.
-
총 70,000개의 흑백(그레이스케일) 이미지로 이루어져 있으며, 60,000개는 학습용, 10,000개는 테스트용이다. 각 이미지는 28x28 픽셀 크기의 정사각형 형태이다.
❓ Cifar_10 데이터셋이란?
-
컴퓨터 비전 분야에서 이미지 분류 모델의 성능을 평가하기 위해 널리 사용되는 컬러 이미지 데이터셋이다.
-
총 60,000개의 컬러(RGB, 3채널) 이미지로 이루어져 있으며, 50,000개는 학습용, 10,000개는 테스트용이다. 각 이미지는 32x32 픽셀 크기이다.

2. 데이터 전처리 및 모델 구조
Mnist 데이터셋
-
데이터: (60000, 28, 28) 크기의 흑백 이미지, 라벨(0~9)
-
전처리: 이미지를 1차원(784)으로 변환 후 0~1 정규화
-
모델:
입력: Dense(3072)
출력층: Dense(10, softmax) (은닉층 없음)
손실함수: sparse_categorical_crossentropy
최적화: SGD
평가: 정확도(acc)
# Mnist 데이터 전처리
train_x1 = train_x.reshape(60000, -1) # 1차원 배열
test_x1 = test_x.reshape(10000, -1) # 1차원 배열
train_x2 = train_x1/255
test_x2 = test_x1/255
print(train_x2.shape) # (60000, 784)
print(test_x2.shape) # (10000, 784)
md = Sequential()
md.add(Dense(10, activation = 'softmax', input_shape = (28*28,)))
md.summary()
md.compile(loss='sparse_categorical_crossentropy', optimizer = 'sgd', metrics=['acc'])
hist = md.fit(train_x2, train_y, epochs = 30, batch_size = 64, validation_split = 0.2)
Cifar_10 데이터셋
-
데이터: (50000, 32, 32, 3) 크기의 컬러 이미지, 라벨(0~9)
-
전처리: 이미지를 1차원(3072)으로 변환 후 0~1 정규화
-
모델:
입력: Dense(3072)
출력층: Dense(10, softmax) (은닉층 없음)
손실함수: sparse_categorical_crossentropy
최적화: SGD
평가: 정확도(acc)
# Cifar_10 데이터 전처리
train_x1 = train_x.reshape(50000, -1) # 1차원 배열
test_x1 = test_x.reshape(10000, -1) # 1차원 배열
train_x2 = train_x1/255
test_x2 = test_x1/255
print(train_x2.shape) #(50000, 3072)
print(test_x2.shape) #(10000, 3072)
md = Sequential()
md.add(Dense(10, activation = 'softmax', input_shape = (32*32*3,)))
md.summary()
md.compile(loss='sparse_categorical_crossentropy', optimizer = 'sgd', metrics=['acc'])
hist = md.fit(train_x2, train_y, epochs = 30, batch_size = 128, validation_split = 0.2)
3. 코드 실행 및 결과 시각화
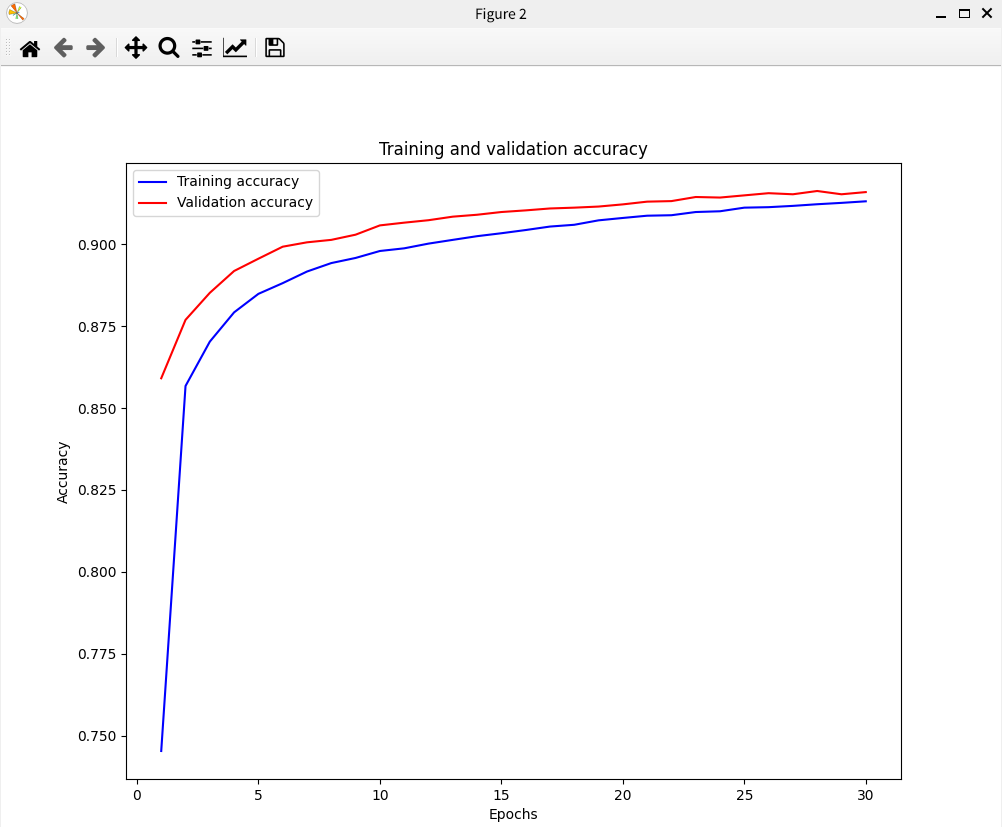
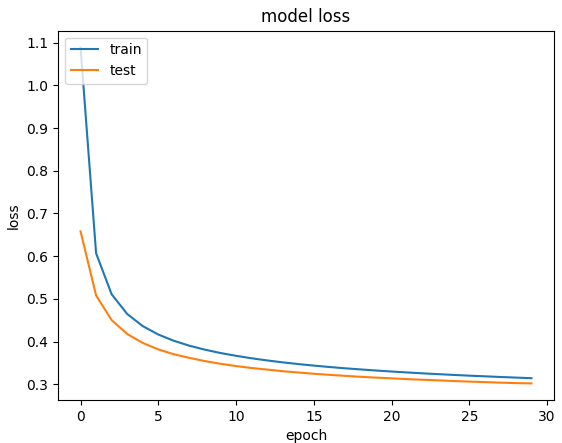
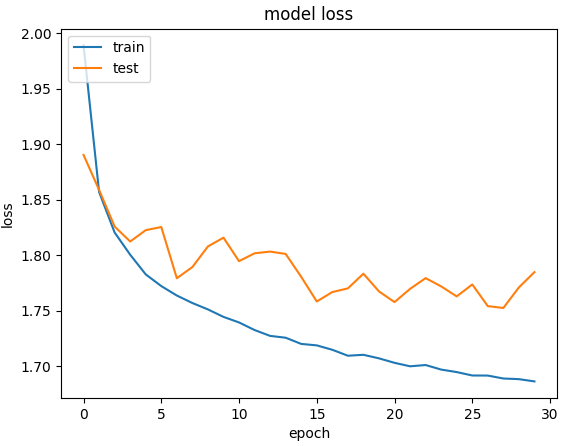
Mnist 데이터셋
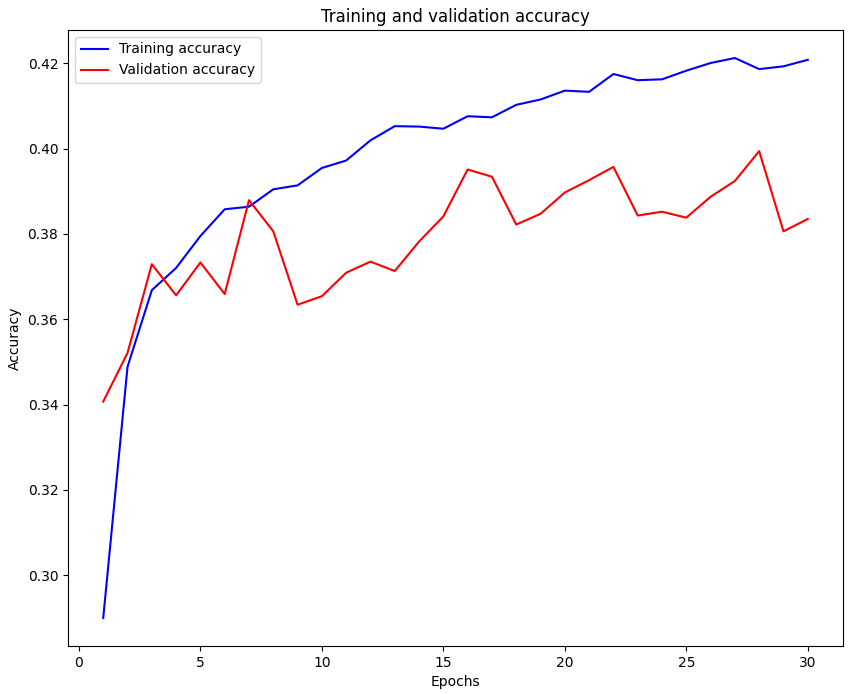
Cifar_10 데이터셋
4. 두 코드의 주요 차이점
| 항목 | MNIST 코드 | CIFAR-10 코드 |
|---|---|---|
| 데이터 타입 | 흑백(1채널), 28x28 | 컬러(3채널), 32x32 |
| 입력 차원 | 784 | 3072 |
| 모델 구조 | 은닉층 ❌ | 은닉층 ❌ |
| 난이도 | 상대적으로 쉬움 | 상대적으로 어려움 |
| 분류 대상 | 손글씨 숫자(0~9) | 10가지 사물 |
| 성능 기대치 | 높은 정확도 달성 용이 | 단순 모델로는 낮은 정확도 |
-
데이터 복잡성: CIFAR-10은 색상, 배경, 형태가 다양해 단순 신경망으로는 분류가 어렵고, MNIST는 단순한 흑백 숫자 이미지라 기본 신경망도 높은 성능을 보임.
5. CIFAR-10 정확도 향상을 위한 하이퍼파라미터 조정 방법
1. 은닉층 추가 및 크기 조정: Dense 레이어(은닉층)를 추가하고, 노드 수를 늘리면 더 복잡한 패턴을 학습
-
은닉층이 없는 구조에 Dense(100, activation=’softmax’)로 하면 100개의 클래스에 대한 확률을 내놓기 때문에, 10개 클래스 분류 문제에서는 올바른 결과 ❌
2. 활성화 함수 변경: 은닉층에 relu 등 비선형 활성화 함수를 적용해 모델 표현력을 높일 수 있다.
3. 배치 사이즈(batch size) 변경: 작은 배치는 더 빠른 업데이트, 큰 배치는 더 안정적인 학습을 유도
4. 에포크 수 조정: 더 오래 학습시키면 성능이 오를 수 있으나, 과적합에 주의
-
과적합은 모델이 학습 데이터의 노이즈나 세부적인 패턴까지 지나치게 학습하여, 새로운 데이터(테스트 데이터)에 대한 일반화 성능이 떨어지는 현상.
-
과적합된 모델은 학습 데이터에서는 높은 정확도를 보이지만, 테스트 데이터에서는 성능이 급격히 떨어진다.
❗과적합 방지법
-
조기 종료(Early Stopping): 검증 데이터의 성능이 더 이상 개선되지 않으면 학습 중단.
-
정규화(Regularization): L1, L2 정규화, 드롭아웃(Dropout) 등을 사용해 모델 복잡도 제어.
-
데이터 증강(Data Augmentation): 학습 데이터를 인위적으로 늘려 모델이 더 일반화되도록 한다.
-
적절한 에포크 수 설정: 검증 성능이 최고일 때 학습을 멈추는 것이 이상적이다.